结构型模式 - 享元模式
意图
享元模式是一种结构型设计模式,它摒弃了在每个对象中保存所有数据的方式,通过共享多个对象所共有的相同状态,让你能在有限的内存容量中载入更多对象。

问题
假如你希望在长时间工作后放松一下, 所以开发了一款简单的游戏: 玩家们在地图上移动并相互射击。 你决定实现一个真实的粒子系统, 并将其作为游戏的特色。 大量的子弹、 导弹和爆炸弹片会在整个地图上穿行, 为玩家提供紧张刺激的游戏体验。
开发完成后, 你推送提交了最新版本的程序, 并在编译游戏后将其发送给了一个朋友进行测试。 尽管该游戏在你的电脑上完美运行, 但是你的朋友却无法长时间进行游戏: 游戏总是会在他的电脑上运行几分钟后崩溃。 在研究了几个小时的调试消息记录后, 你发现导致游戏崩溃的原因是内存容量不足。 朋友的设备性能远比不上你的电脑, 因此游戏运行在他的电脑上时很快就会出现问题。
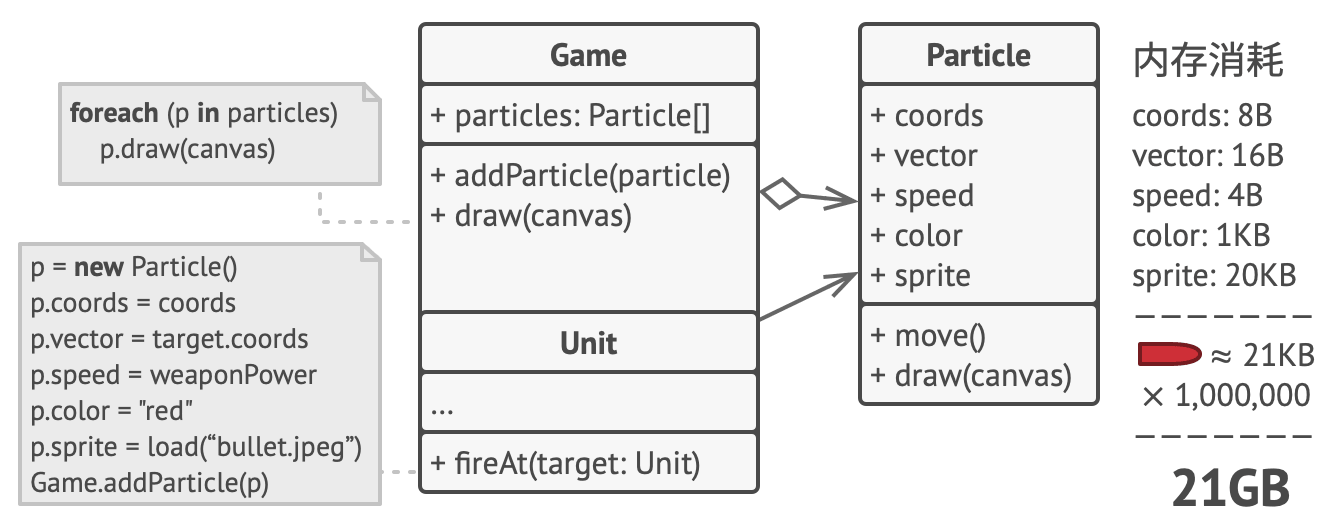
真正的问题与粒子系统有关。 每个粒子 (一颗子弹、 一枚导弹或一块弹片) 都由包含完整数据的独立对象来表示。 当玩家在游戏中鏖战进入高潮后的某一时刻, 游戏将无法在剩余内存中载入新建粒子, 于是程序就崩溃了。
解决方案
仔细观察 粒子Particle类, 你可能会注意到颜色 (color) 和精灵图 (sprite)这两个成员变量所消耗的内存要比其他变量多得多。 更糟糕的是, 对于所有的粒子来说, 这两个成员变量所存储的数据几乎完全一样 (比如所有子弹的颜色和精灵图都一样)。
每个粒子的另一些状态 (坐标、 移动矢量和速度) 则是不同的。 因为这些成员变量的数值会不断变化。 这些数据代表粒子在存续期间不断变化的情景, 但每个粒子的颜色和精灵图则会保持不变。
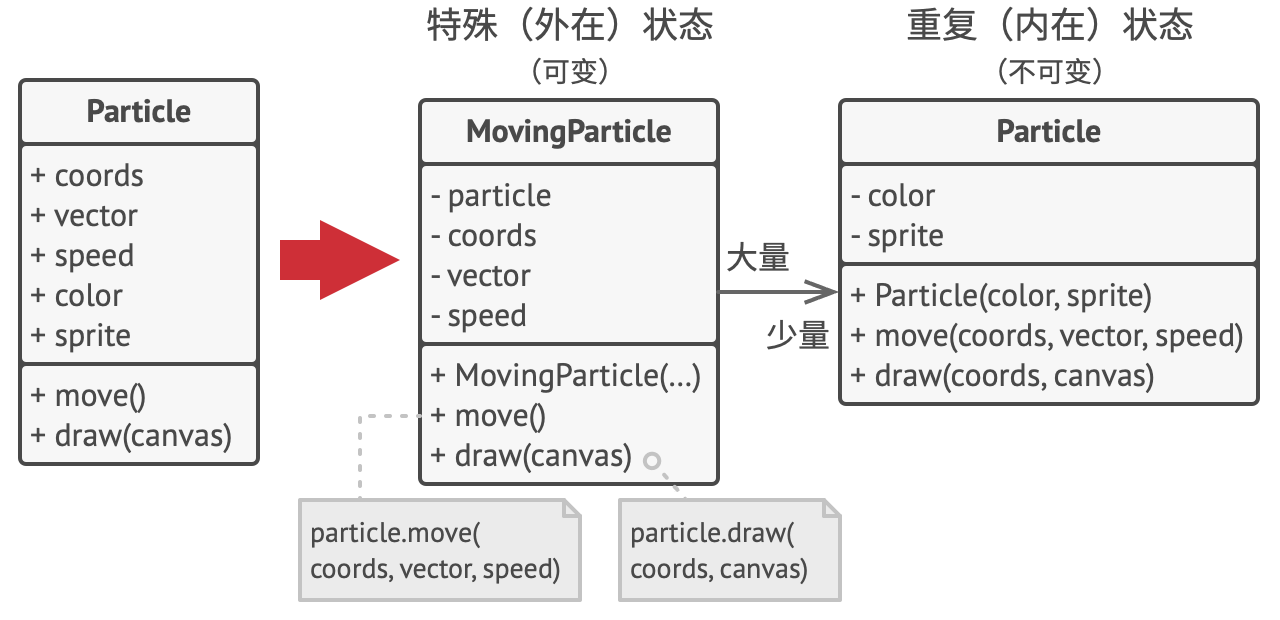
对象的常量数据通常被称为内在状态, 其位于对象中, 其他对象只能读取但不能修改其数值。 而对象的其他状态常常能被其他对象 “从外部” 改变, 因此被称为外在状态。
享元模式建议不在对象中存储外在状态, 而是将其传递给依赖于它的一个特殊方法。 程序只在对象中保存内在状态, 以方便在不同情景下重用。 这些对象的区别仅在于其内在状态 (与外在状态相比, 内在状态的变体要少很多), 因此你所需的对象数量会大大削减。
让我们回到游戏中。 假如能从粒子类中抽出外在状态, 那么我们只需三个不同的对象 (子弹、 导弹和弹片) 就能表示游戏中的所有粒子。 你现在很可能已经猜到了, 我们将这样一个仅存储内在状态的对象称为享元。
外在状态存储
那么外在状态会被移动到什么地方呢? 总得有类来存储它们, 对不对? 在大部分情况中, 它们会被移动到容器对象中, 也就是我们应用享元模式前的聚合对象中。
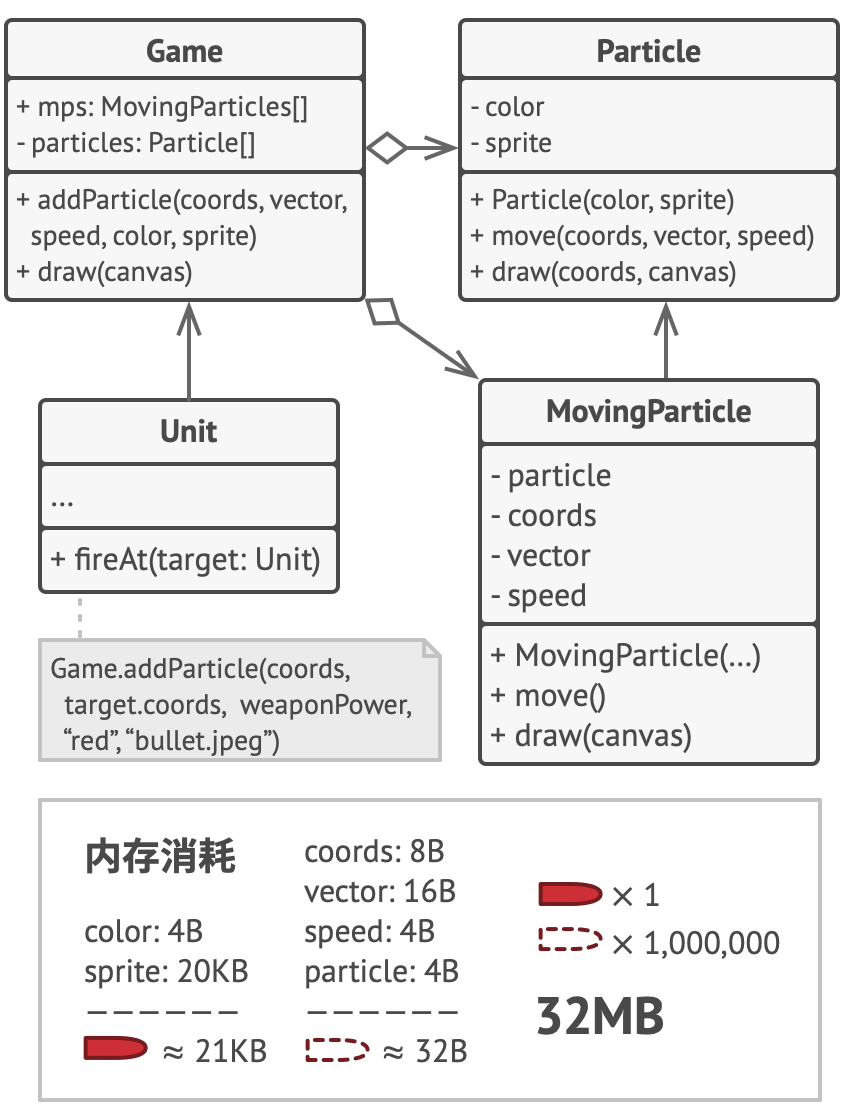
在我们的例子中, 容器对象就是主要的 游戏Game对象, 其会将所有粒子存储在名为 粒子particles的成员变量中。 为了能将外在状态移动到这个类中, 你需要创建多个数组成员变量来存储每个粒子的坐标、 方向矢量和速度。 除此之外, 你还需要另一个数组来存储指向代表粒子的特定享元的引用。 这些数组必须保持同步, 这样你才能够使用同一索引来获取关于某个粒子的所有数据。
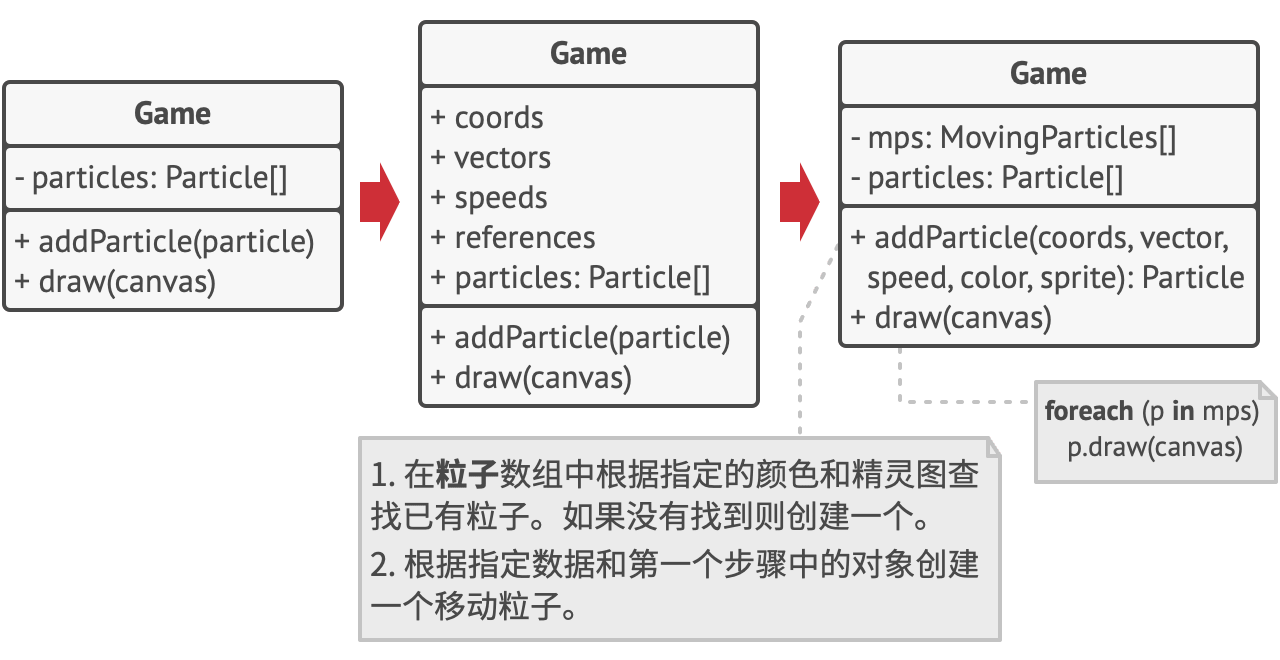
更优雅的解决方案是创建独立的情景类来存储外在状态和对享元对象的引用。 在该方法中, 容器类只需包含一个数组。
稍等! 这样的话情景对象数量不是会和不采用该模式时的对象数量一样多吗? 的确如此, 但这些对象要比之前小很多。 消耗内存最多的成员变量已经被移动到很少的几个享元对象中了。 现在, 一个享元大对象会被上千个情境小对象复用, 因此无需再重复存储数千个大对象的数据。
享元与不可变性
由于享元对象可在不同的情景中使用, 你必须确保其状态不能被修改。 享元类的状态只能由构造函数的参数进行一次性初始化, 它不能对其他对象公开其设置器或公有成员变量。
享元工厂
为了能更方便地访问各种享元, 你可以创建一个工厂方法来管理已有享元对象的缓存池。 工厂方法从客户端处接收目标享元对象的内在状态作为参数, 如果它能在缓存池中找到所需享元, 则将其返回给客户端; 如果没有找到, 它就会新建一个享元, 并将其添加到缓存池中。
你可以选择在程序的不同地方放入该函数。 最简单的选择就是将其放置在享元容器中。 除此之外, 你还可以新建一个工厂类, 或者创建一个静态的工厂方法并将其放入实际的享元类中。
享元模式结构
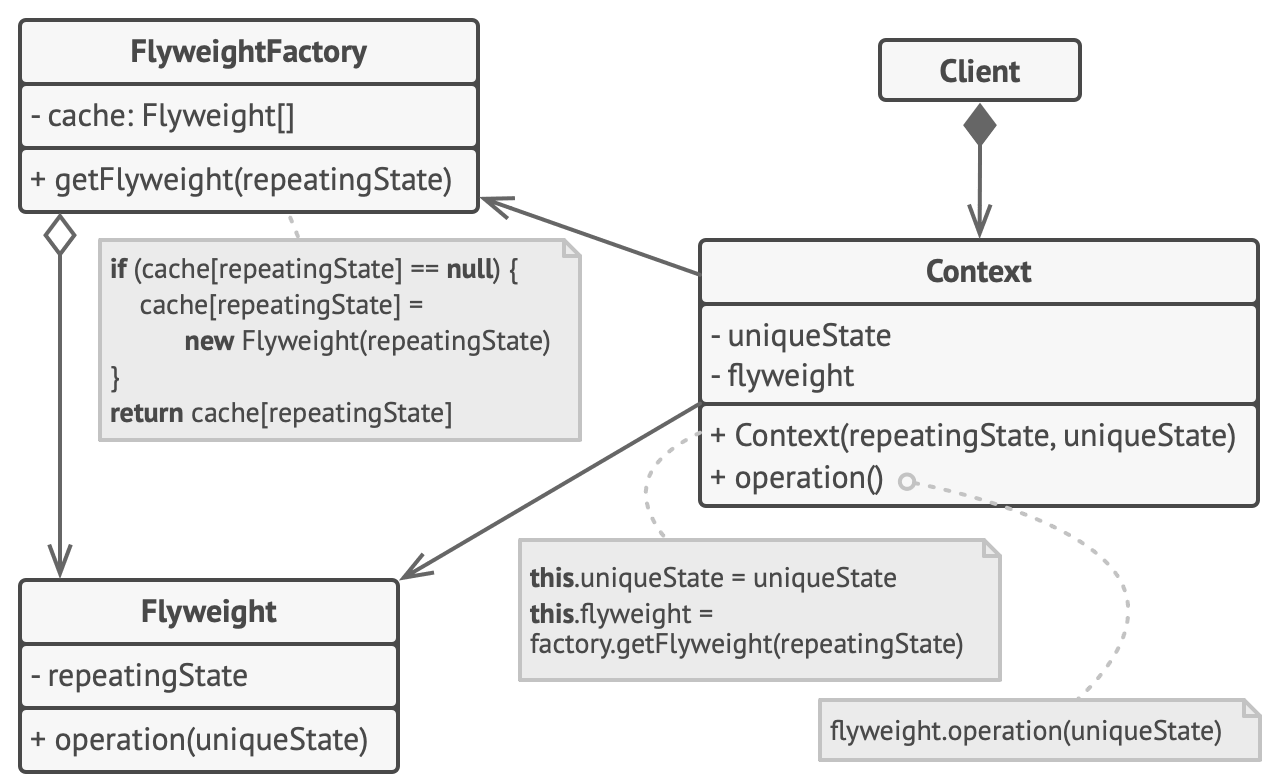
伪代码
在本例中,享元模式能有效减少在画布上渲染数百万个树状对象时所需的内存。
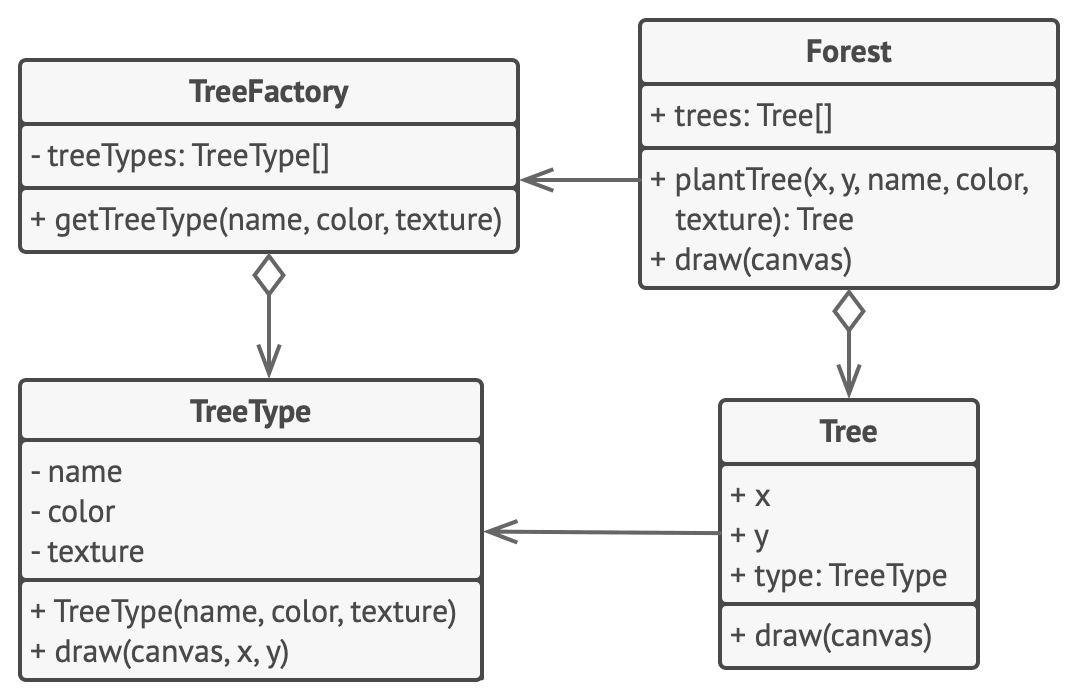
该模式从主要的 树Tree类中抽取内在状态, 并将其移动到享元类 树种类TreeType之中。
最初程序需要在多个对象中存储相同数据, 而现在仅需在几个享元对象中保存数据, 然后在作为情景的 树对象中连入享元即可。 客户端代码使用享元工厂创建树对象并封装搜索指定对象的复杂行为, 并能在需要时复用对象。
// 享元类包含一个树的部分状态。这些成员变量保存的数值对于特定树而言是唯一
// 的。例如,你在这里找不到树的坐标。但这里有很多树木之间所共有的纹理和颜
// 色。由于这些数据的体积通常非常大,所以如果让每棵树都其进行保存的话将耗
// 费大量内存。因此,我们可将纹理、颜色和其他重复数据导出到一个单独的对象
// 中,然后让众多的单个树对象去引用它。
class TreeType is
field name
field color
field texture
constructor TreeType(name, color, texture) { …… }
method draw(canvas, x, y) is
// 1. 创建特定类型、颜色和纹理的位图。
// 2. 在画布坐标 (X,Y) 处绘制位图。
// 享元工厂决定是否复用已有享元或者创建一个新的对象。
class TreeFactory is
static field treeTypes: collection of tree types
static method getTreeType(name, color, texture) is
type = treeTypes.find(name, color, texture)
if (type == null)
type = new TreeType(name, color, texture)
treeTypes.add(type)
return type
// 情景对象包含树状态的外在部分。程序中可以创建数十亿个此类对象,因为它们
// 体积很小:仅有两个整型坐标和一个引用成员变量。
class Tree is
field x,y
field type: TreeType
constructor Tree(x, y, type) { …… }
method draw(canvas) is
type.draw(canvas, this.x, this.y)
// 树(Tree)和森林(Forest)类是享元的客户端。如果不打算继续对树类进行开
// 发,你可以将它们合并。
class Forest is
field trees: collection of Trees
method plantTree(x, y, name, color, texture) is
type = TreeFactory.getTreeType(name, color, texture)
tree = new Tree(x, y, type)
trees.add(tree)
method draw(canvas) is
foreach (tree in trees) do
tree.draw(canvas)享元模式适合应用场景
仅在程序必须支持大量对象且没有足够的内存容量时使用享元模式。
应用该模式所获的收益大小取决于使用它的方式和情景。 它在下列情况中最有效:
- 程序需要生成数量巨大的相似对象
- 这将耗尽目标设备的所有内存
- 对象中包含可抽取且能在多个对象间共享的重复状态。
实现方式
将需要改写为享元的类成员变量拆分为两个部分:
- 内在状态: 包含不变的、 可在许多对象中重复使用的数据的成员变量。
- 外在状态: 包含每个对象各自不同的情景数据的成员变量
保留类中表示内在状态的成员变量, 并将其属性设置为不可修改。 这些变量仅可在构造函数中获得初始数值。
找到所有使用外在状态成员变量的方法, 为在方法中所用的每个成员变量新建一个参数, 并使用该参数代替成员变量。
你可以有选择地创建工厂类来管理享元缓存池, 它负责在新建享元时检查已有的享元。 如果选择使用工厂, 客户端就只能通过工厂来请求享元, 它们需要将享元的内在状态作为参数传递给工厂。
客户端必须存储和计算外在状态 (情景) 的数值, 因为只有这样才能调用享元对象的方法。 为了使用方便, 外在状态和引用享元的成员变量可以移动到单独的情景类中。
享元模式优缺点
- 优点:
- 如果程序中有很多相似对象,那么你将可以节省大量内存。
- 缺点:
- 你可能需要牺牲执行速度来换取内存,因为他人每次调用享元方法时都需要重新计算部分情景数据。
- 代码会变得更加复杂。团队中的新成员总是会问:“为什么要像这样拆分一个实体的状态?”。