10. 递归
概念
.....
递归方程求解--替换法
如例 1:使用
来替换
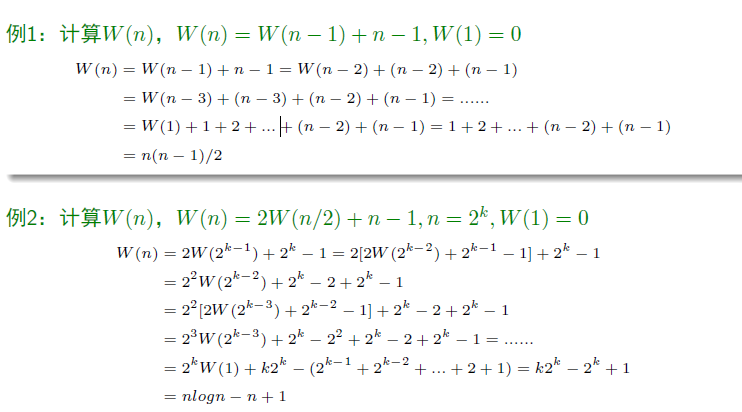
递归方程求解--主定理
主定理:设
是一个非递归函数,并且满足递推式 其中
如果 ,那么
- 当
时, - 当
时, - 当
时,
递归类型
减一算法
算法利用一个规模为 n 的实例和规模为 n-1 的给定实例之间的关系来对问题求解(插入排序)
减常因子算法
规模为 n 的实例化简为一个规模为
的给定实例来求解(折半查找)
分治算法
给定实例划分为若干个较小的实例,对每个实例递归求解,然后再把较小的实例合并成给定实例的一个解(快速排序,合并排序)
汉诺塔
假设有 A,B,C 三根柱子,在 A 柱上放着 n 个圆盘,其中小圆盘放在大圆盘的上面。我们的目的是从 A 柱将这些圆盘移动到 C 柱上去,在必要的时候可借助 B 柱,每次只能移动一个盘子,并且不允许大盘子在小盘子上面。问需要多少次的移动?
解决办法
- 把 n-1 个盘子递归地从 A 移动到 B;
- 把第 n 个盘子从 A 移动到 C;
- 把 n-1 个盘子递归地从 B 移动到 C;
- 若 n 等于 1, 直接把盘子从 A 移动到 C;
function Hanoi(A,C, n)
if n = 1 then
move(A,C)
else
Hanoi(A,B, n − 1)
move(A,C)
Hanoi(B,C, n − 1)
end if
end function其他
- 递归仅提供了一种分析手段,本身不具有降低算法复杂性地性质;
- 应该谨慎使用递归算法,它的简洁额能会掩盖其低效的事实;
分治策略
基本概念
- 将问题划分为同一类型的若干子问题,子问题最好规模相同;
- 对这些子问题求解(通常使用递归的方式);
- 合并这些子问题的解,以得到原问题的解;
可以使用主定理对分治法的复杂度进行分析
为什么分治法会比蛮力法效率高?
不一定所有的问题分治就一定比蛮力好,只是往往比其好,所以就需要我们进行算法效率的分析了
那怎么直观理解分治法效率比较高呢?
TODO
合并排序
def merge(left, right):
'''
对两个有序数组合并为一个有序数组
'''
result = []
while left and right:
if left[0] < right[0]:
result.append(left.pop(0))
else:
result.append(right.pop(0))
if left:
result += left
if right:
result += right
return result
def merge_sort(numberlist):
'''
递归实现分治的思想
'''
if len(numberlist) <= 1:
return numberlist
mid = len(numberlist) // 2
left = numberlist[:mid]
right = numberlist[mid:]
left = merge_sort(left)
right = merge_sort(right)
return merge(left, right)算法效率分析
基本操作为元素之间的比较
比较次数的递推关系:
最坏情况下,
; 最坏情况下效率:
根据主定理可得
合并排序在最坏情况下的比较次数十分接近基于比较的排序算法的理论上能够达到的最少比较次数
合并排序的主要缺点是需要线性的额外空间
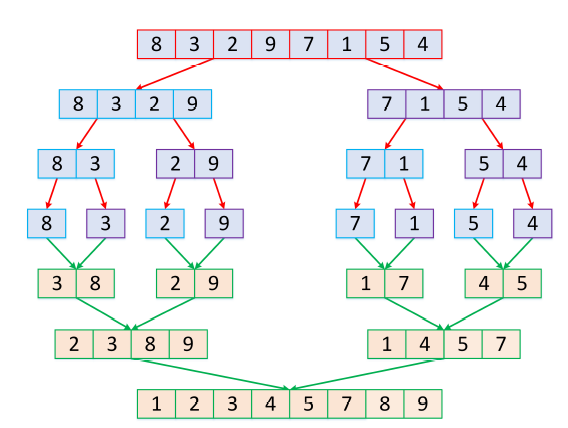
快速排序
合并排序按照元素的位置划分并合并的方式进行排序。划分过程很快,主要工作在合并子问题。子问题递归排序后,合并很简单(拼接),主要工作在如何划分(如何有效地划分?),这就是快速排序算法。
def quick_sort(array):
if len(array) < 2:
return array
else:
pivot = array[0]
less = [i for i in array[1:] if i <= pivot]
greater = [i for i in array[1:] if i > pivot]
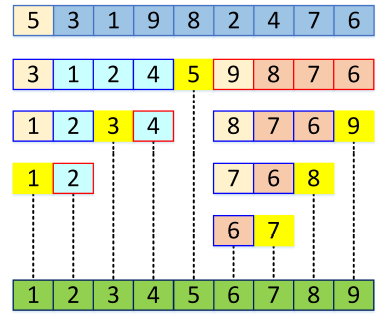
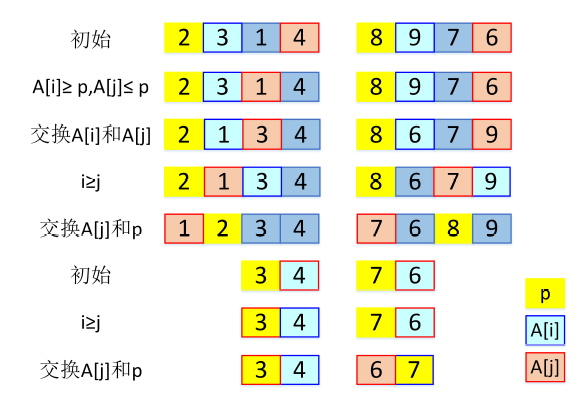
return quick_sort(less) + [pivot] + quick_sort(greater)霍尔划分
更好地理解快速排序
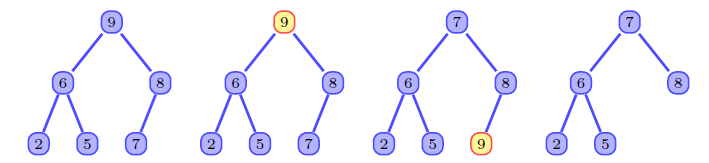
堆排序
选择排序的一种,每次选择大根堆(小根堆)的堆顶,然后放入有序区(堆底)
- 建堆
- 删除最大键

def heap_sort(numberlist):
length = len(numberlist)
def sift_down(start, end):
root = start
while True:
child = 2 * root + 1
if child > end:
break
if child + 1 <= end and numberlist[child] < numberlist[child + 1]:
child += 1
if numberlist[root] < numberlist[child]:
numberlist[root], numberlist[child] = numberlist[child], numberlist[root]
root = child
else:
break
# 创建最大堆
for start in range((length - 2) // 2, -1, -1):
sift_down(start, length - 1)
# 堆排序
for end in range(length - 1, 0, -1):
numberlist[0], numberlist[end] = numberlist[end], numberlist[0]
sift_down(0, end - 1)
return numberlist算法效率分析
第一阶段(构造堆--自底向上)复杂度为
; 第二阶段(删除最大键)键值比较次数:
总的效率为
(任何情况),且无需额外的存储空间 对于随机的输入,堆排序比快速排序运行的慢
插入排序
无序区向有序区依次扫描插入
def insert_sort(data):
for k in range(1, len(data)):
cur = data[k]
j = k
while j > 0 and data[j - 1] > cur:
data[j] = data[j - 1]
j -= 1
data[j] = cur
return data性能比较
| 算法 | 最好效率 | 最差效率 | 平均效率 |
|---|---|---|---|
| 选择排序 | |||
| 冒泡排序 | |||
| 插入排序 | |||
| 合并排序 | |||
| 快速排序 | |||
| 堆排序 |
前面还有常数
- 合并排序的主要缺点是需要额外空间;
- 平均来说,快速排序的运行时间比合并排序要快一点;
- 堆排序不需要额外空间,比快速排序平均运行时间要多一点;
选择问题
选最大最小
- 调用顺序比较找最大和最小算法,先找出最大,然后把最大从 L 中删除,继续找出最小;
- 比较次数:
找第二大
- 调用顺序比较找最大算法,先找出最大,然后把最大从 L 中删除,继续找出最大;
- 比较次数:
选择第 K 小-快速选择
分治法求解思路
- 用某个元素 m*作为比较标准将 S 划分成 S1 与 S2;
- 如果
,则在 S1 中找第 k 小; - 如果
,则在 m*是第 k 小; - 如果
,则在 S2 中找第 小; - 如此重复划分过程,直到
; - 划分方法:Lomuto 算法,Hoare 划分方法;
实例:寻找 9 个数的中位数(k=5)
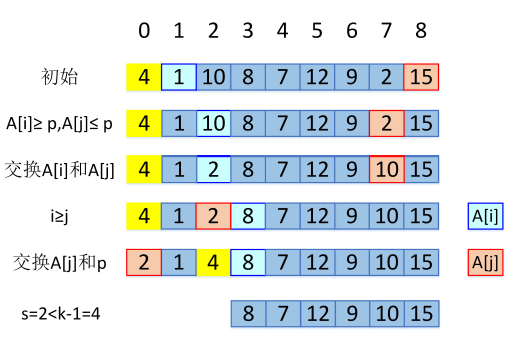
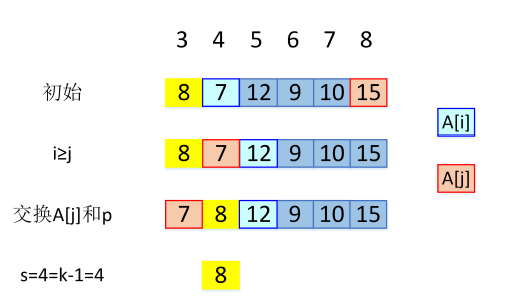
#快速选择
import numpy as np
def LomutoPartition(A,l,r):
p=A[l]
s=l
for i in range(l+1,r+1):
if A[i]<p:
s=s+1
A[s],A[i]=A[i],A[s]
A[s], A[l] = A[l], A[s]
return s
def Quickselect(A,l,r,k):
s=LomutoPartition(A,l,r)
if s==l+k-1:
print(A)
return A[s]
elif s>l+k-1:
A[s]=Quickselect(A,l,s-1,k)
return A[s]
else:
A[s]=Quickselect(A,s+1,r,l+k-1-s)
return A[s]
# test
A=np.random.randint(10,size=10)
l=0
r=len(A)-1
kk=Quickselect(A,l,r,6)
print(kk)分治进阶
大整数乘法
TODO
矩阵乘法
TODO
最近对问题
TODO
凸包问题
TODO